Hello! I am a assistant professor at NYU. I'm also a research scientist at Google DeepMind, part of the GenAI/nano 🍌 team.
Before that I was a research scientist at Facebook AI Research (FAIR), Menlo Park for four years.
Most human and animal knowledge arises from sensory experiences and their interactions with the environment. I believe that achieving human-like intelligence requires moving beyond language-only systems toward world models that learn directly from continuous, real-world sensory input---systems capable of understanding, creating, reasoning, planning, and developing commonsense about the physical world.
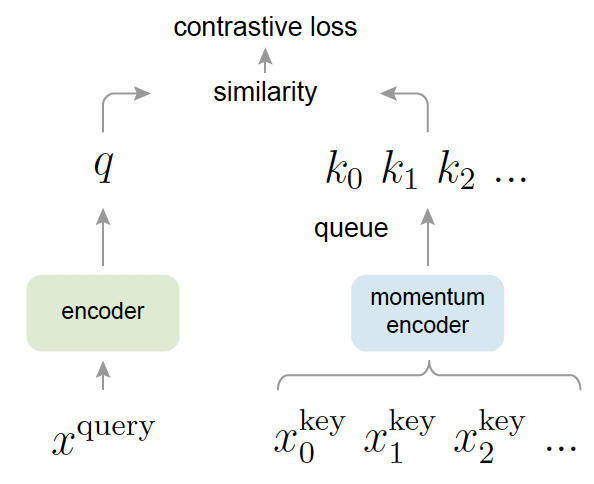
To advance understanding, I have developed some of the most widely adopted architectures and representation learning systems in computer vision, including this, this, and this. You can also explore our recent work here, which pushes the boundaries of multimodal intelligence and spatial supersensing across images and videos. For generation, I co-created diffusion transformers (DiT), a framework that powers most of today's leading generative systems like Sora. We've since accelerated training by orders of magnitude, as explored in this and this.
My research has been cited over 90,000 times (as of Dec 2025), and I am honored to be a recipient of the Marr Prize Honorable Mention, NSF CAREER Award, AISTATS Test-of-Time Award, and the PAMI Young Researcher Award.
I will be on leave from NYU in Spring/Summer 2026.
I was fortunate to work with many exceptionally talented students and interns during my time at FAIR, GDM, and NYU. Many of whom are now leaders in the AI field. These include Sanghyun Woo (nano banana, GDM), Bill Peebles (Head of Sora, OpenAI), Eric Mintun (Sora, OpenAI), Zihan Zhang (OpenAI), Zhuang Liu (professor at Princeton), Jiaxuan You (professor at UIUC), Bingyi Kang (Researcher at TikTok), Demi Guo (Cofounder, Pika), Xun Huang (Cofounder, stealth startup), Ji Hou (Meta GenAI), Chenxi Liu (Meta, TBD Lab), Norman Mu (xAI), Suppakit Waiwitlikhit (xAI), and many others.
Selected Publications
(* indicate equal contribution)
For full publication list, please refer to my Google Scholar page.
(Actually, the best way to stay updated on my latest research is to check there, as I may not update this website regularly.)
Diffusion Transformers with Representation Autoencoders

 Google Scholar page.
Google Scholar page.